
制程封装架构全面升级,谁说英特尔不行了?
在8月13日举办的2020架构日上,英特尔发布了长达233页的技术更新,覆盖制程、封装、架构、软件等“六大技术支柱”的方方面面。作为摩尔定律的提出者,英特尔一方面围绕晶体管密度和性能,推动摩尔定律在10nm以下的发展;另一方面,英特尔正在从晶体管“Reliance(依赖)”走向晶体管“Resilient(弹性)”,通过“六大技术支柱”,推动计算性能在当前和“后摩尔时代”的持续增长,并形成了面向异构计算时代的整体交付能力,以更有效地应对智能时代的计算挑战。
制程工艺并未止步
2007年,英特尔提出了“Tick Tock”发展模式,通过制程演进与微架构更新,轮换推动处理器性能提升。在2016年,英特尔将“Tick Tock”调整为“PAO”,通过制程、微架构、优化三种方式轮流推动处理器性能的升级。
在架构日上,英特尔发布了Superfin技术。作为FinFet的增强版本,Superfin属于“O”的范畴,是针对10nm的晶体管强化工艺。虽然没有用“10nm+”来命名,但Superfin对于10nm工艺的提升超过15%,包含更高的驱动电流、通道迁移率,以及更好的芯片互联性等。
英特尔院士Ruth Brain称,Superfin实现了英特尔史上最强大的单节点内性能增强,其提升程度可媲美全节点转换。
在10nm Superfin之后,英特尔还将发布10nm 增强型Superfin技术,进一步提升芯片性能和互联能力,并针对数据中心场景进行进一步的优化。
10nm Superfin的性能将达到何种程度,也引起了业内的广泛讨论。随着制程进入14nm以内,摩尔定律的实现越来越难,逐渐逼近物理极限。即便晶体管密度提升幅度不足一倍,也冠以新的制程节点,已经成为许多代工厂商的选择,这也让节点命名越来越具备市场行为的色彩。
可是,在10nm及以下,英特尔仍在遵循摩尔定律的硬性指标。其10nm节点的晶体管密度达到100.8MTr/mm2,即每平方毫米内包含超过1亿个晶体管,是14nm节点的2.7倍。在晶体管密度、鳍片间距、栅极间距等指标上,英特尔10nm已经超过了台积电、三星的7nm制程。
如果Superfin的性能,能堪比全节点的转换,那么在10nm指标能够对标友商7nm的基础上,Superfin能否对标友商7nm工艺的增强版甚至更先进的工艺节点,不免令人浮想联翩。当然,制程工艺的先进性必须在产品中得到验证。英特尔的下一代处理器Tiger Lake,将成为首个采用10nm Superfin的处理器。当下该处理器已经投产,预计OEM采用Tiger Lake设计的产品将在今年之内上市。而10nm增强型技术,也将在下一代至强可扩展处理器Sapphire Rapids得到验证。
从晶体管Reliance走向晶体管Resilient
无论是增加晶体管数量还是提升晶体管性能,都属于制程工艺的范畴,代表着英特尔继续追随摩尔定律的决心。与此同时,随着制程微缩逼近极限,如何在“后摩尔时代”延续计算能力的指数级增长,成为半导体产业的重要课题。
在架构日上,英特尔首席架构师Raja KoduriRaja提到了“Transistor Resilient(晶体管弹性)”的概念。简单来说,这是与完全依赖晶体管相对的产品开发策略,通过架构、封装、软件等技术的“组合拳”,实现产品性能的提升。
架构是硬件设计的基础,对处理器的性能和功耗表现起到决定性作用。本次架构日,英特尔发布了下一代微架构“Willow Cove”。为满足下游客户的多样化需求,Willow Cove提供了更大的动态范围。相比上一代架构Sunny Cove,Willow Cove可以用更低的电压达到同样的主频,在提高电压的情况下,可以达到5GHz左右的最高主频,满足创意工作者、游戏爱好者对生产力的不同需求。
同样在架构日亮相的,还有英特尔的GPU架构Xe,这也是继1998年发布的i740之后,英特尔再度进军独显市场。Xe提供LP、HP、HPG、HPC四种微架构。LP针对PC和移动计算平台等功耗敏感场景,拥有96组EU单元,与Willow Cove类似,LP可以通过加高电压获得1.8GHz甚至更高的主频,提供更强的输出功率。当下,基于LP架构的独显产品“DG1”已经实现量产。HP版本面向数据中心级、机架级场景所需的媒体性能,基于英特尔EMIB技术,HP能够在单封装中提供千万亿浮点运算规模的AI性能和机架级的媒体性能,首款产品已经向数据中心客户出样。HPG面向游戏领域,基于GDDR6的新内存子系统提高性价比,并具备当前热门的光线跟踪能力。HPC架构则针对高性能计算领域,满足大规模的集成部署需要。
硬件能力的释放,必须基于软件的通信和调度。在Xe的设计理念中,英特尔强调了“软件优先”的原则,提升了GPU的编译和驱动效率,实现了GPU根据用户配置进行性能优化以及可变频率着色、即时游戏调整、感知自适应游戏锐化等功能,让GPU能够更好地满足3D、媒体、显示、计算等不同工作负载的计算需求。
先进封装向来被视为摩尔定律的“救星”,在不依赖工艺缩小的前提下,先进封装可以继续提升芯片的系统集成度。芯片的连接触电密度、单比特功耗、扩展性,是英特尔发展先进制程的主要指标。当下,英特尔已经形成了2.5D封装EMIB、3D封装Foveros,以及混合2D和3D封装的Co-EMIB等先进封装方案。在架构日,英特尔发布了“混合结合”技术,能够加速实现10微米及以下的凸点间距,较Fovreros 25-50微米的凸点间距有明显提升,并优化了互连密度、带宽和功率表现,进一步提升芯片系统的计算效能。
基于异构整合提升交付能力
新冠肺炎疫情是搅动全球经济的黑天鹅。疫情的冲击导致全球消费者信心下降,手机等消费终端出货量出现回落。与此同时,远程服务和“宅经济”异军突起,服务器成为疫情之下驱动半导体增长的重要动能。
半导体作为精密产业,生产周期较长。面对疫情带来的市场需求变化,半导体企业能否利用技术积累和产业链合作生态,保持快速交付的能力,实现“化危为机”,成为企业运营能力的试金石。从财报来看,英特尔抓住了市场变化带来的机遇。当季,英特尔以PC为中心的传统强势业务同比增长7%,数据中心业务则强势增长43%,营收和净利润均实现超过超过20%的增长。
在架构日上,英特尔展现了基于分解设计和软件平台的异构集成,进一步提升不同产品交付能力的策略。
所谓异构计算,是将多种架构、功能的芯片封装在一个SoC,以处理或加速不同工作负载的硬件集成方式。如果像拼搭积木一样,将生产好的芯片、裸片封装在一起,形成系统级芯片,将显著提升硬件产品的交付速度,满足AI、IOT等场景对于芯片的多样化、差异化需求。
通过分解设计,英特尔将异构计算芯片化繁为简,分解为不同的部分,分别进行整合和验证。由于不是一次性整合所有芯片,而是按照CPU、GPU、IO等计算功能分别去做,预生产的芯片、已经成熟的IP无需再次进行工艺验证,可直接复用。从而缩短了开发和验证时间,降低了差错率,也增强了系统级芯片的灵活性,可以更加便捷地进行功能扩展。
在异构计算时代,利用软件系统隐藏硬件复杂性,让异构计算平台以“黑盒”的方式被客户获取并使用,对于产品的开发和交付尤为重要。oneAPI是英特尔生态构建的野心之作,提供了跨平台的工具链、编译器、调试工具和迁移工具等,以及统一的开发环境,这意味着用户不必为了不同的芯片架构重新学习编程知识,从而降低了异构计算的开发难度。oneAPI Gold版本将于今年晚些时候发布,为开发人员提供在标量、矢量、距阵和空间体系结构上保证产品级别的质量和性能的解决方案。英特尔于7月发布的第八版的oneAPI Beta,为分布式数据分析带来了新的功能和提升,包含渲染性能、性能分析以及视频和线程文库。
基于更加灵活的硬件集成方式和强调易用性的软件平台,英特尔可以更有效地打通芯片级、系统级、软件级异构能力,提供定制化的产品方案和更短的交付周期。从底层的制程和封装,到中层的架构、存储、互连、软件,到最顶层的安全,“六大技术支柱”都将在英特尔的异构计算战略中发挥作用,共同应对智能时代数据量指数级增长和数据形态更加多元的算力挑战。






站内头条
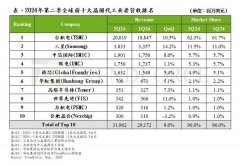
供应链急单+AI需求,第二季全球前十大晶圆代工产值季增9.6%
2024-09-13
AI PC市场渐热,苹果强大AI芯片M4 问世
2024-05-08
三星获得高达64亿美元的芯片法案资金,以扩大德克萨斯州的半导体业务
2024-04-16
漂亮手机来了,华为P系列改名Pura
2024-04-16
ASML推出全新Hyper-NA EUV技术,预计2030年问世引领半导体新篇章
2024-02-28